
¿Estás trasteando con la Consola de Búsqueda de Google Webmaster Tools y aparecen errores de datos estructurados, informando de que faltan campos en algunas de las secciones del sitio web, como author, entry-title y/o updated?
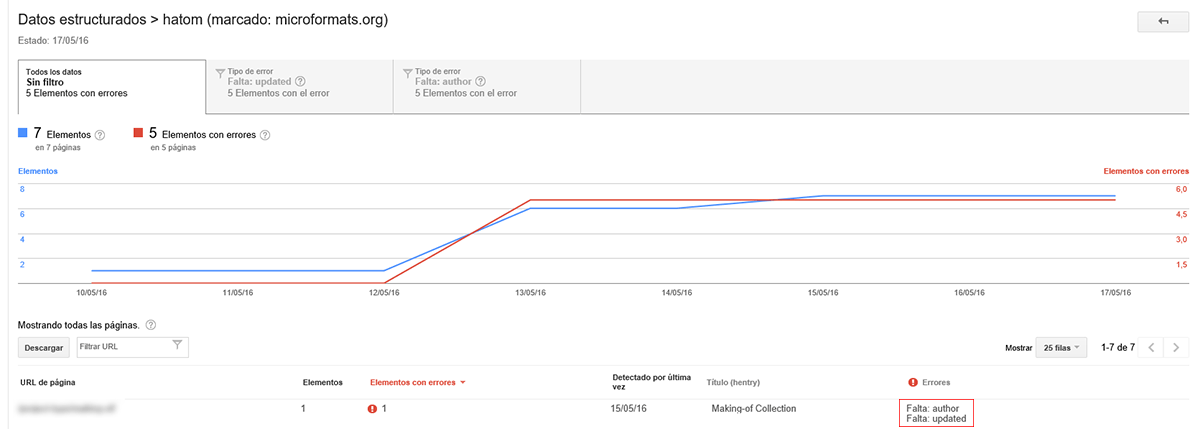
Si te has encontrado con errores de datos estructurados y no sabes de qué va el tema, probablemente estás usando un gestor de contenidos como WordPress u otro Framework de desarrollo web que usa microformatos con datos incompletos en algunas de las secciones.
Es posible que finalmente no resulte ser un detalle vital, pero en estos días de locura SEO, parece que minimizar cualquier error que pudiera afectar nuestro posicionamiento resulta ser lo más sensato, siempre y cuando haya una solución factible. Entonces, en este caso, ¿cómo lo solucionamos?
Aclarando conceptos
¿Qué es hentry? Los microformatos y hAtom
Los microformatos son extensiones del lenguage HTML que permiten marcar contenido publicado en Internet en función de sus características, por ejemplo: gente, organizaciones, localizaciones, entradas en blogs, productos, comparativas, etc.
Los sitios web pueden usar (y usan, para optimizar su SEO) microformatos para permitir a los motores de búsqueda y otras herramientas localizar e indexar correctamente su contenido. A los buscadores, como Google, les gustan los microformatos porque son una manera estandarizada de clasificar la información en la red.
Dentro de los microformatos existen varias especificaciones y una de ellas, hAtom, fue ideada para identificar entradas en blogs o artículos de noticias. La especificación hAtom usa la clase raíz hentry para indicar la presencia de una entrada de tipo hAtom, pero a su vez requiere de otras clases para que se considere completa, y tal como habrás sospechado a estas alturas, dos de ellas son las etiquetas published y author.
Identificando el problema
hAtom fue ideado para facilitar la sindicación o redifusión web (los RSS) pero el estándard ha ganado popularidad y Google usa estos datos estructurados para formar Rich Snippets (fragmentos enriquecidos) para clasificar la información y mostrar los resultados en las búsquedas.
Dado que WordPress se usa principalmente como plataforma para blogging (seguramente aplique a otros CMS o Framweworks de desarrollo web ideados para el mismo público) incorpora de serie el uso de hatom-hentry para las entradas del blog, para que se beneficien de tener datos ricos con los que ser fácilmente identificadas e indexadas por los buscadores. Concretamente se añade el marcado necesario en la función post_class().
En general, esto no representa un gran problema cuando nos ceñimos a entradas del blog, ya que la mayoría de temas (aunque no todos) incluyen las etiquetas author vcard y updated en el HTML, puesto que es lógico en este caso: siempre que pensamos en una entrada de blog, asociamos un autor y una fecha de creación/actualización del contenido para dicha entrada. ¿Pero qué sucede cuando el tipo de contenido es otro, por ejemplo una página estática, o los archivos para categorías, tags o entradas personalizadas?
Depende de cómo se haya implementado el tema de WordPress que estemos usando, pero es bastante habitual que no se haya tenido en cuenta añadir estas etiquetas en todos los casos necesarios, a juzgar por lo habitual que parece ser el problema, aunque en cierta manera parece lógico, pues no estamos hablando de entradas del blog como tal.
El problema surge cuando algunos temas deciden usar el mismo código para generar el HTML básico para el contenido de la página (incluyendo siempre la clase hentry) pero luego deciden en función de si es una entrada u otro tipo de contenido, «escupir» la información meta del autor y fecha. En este último caso es cuando nos vamos a encontrar con errores en Search Console, ya que Google espera sí o sí estos metadatos cuando encuentra la clase raíz hentry.
Posibles soluciones para eliminar los errores de datos estructurados
Básicamente la solución para eliminar errores de datos estructurados pasa o bien por eliminar la etiqueta hentry de aquellas páginas web que no sean entradas de blog o similar, o por hacer que las clases faltantes (author vcard y updated) sean incluídas en todas las páginas en donde se ha añadido la clase hentry, independientemente de si son entradas de blog o no.
Eliminar hentry en las secciones que no sean entradas del blog
Probablemente la solución más directa y en cierta manera coherente con la finalidad para la que se especificó el estándard hatom. Si el tema que usamos ya está añadiendo los datos correctamente a las entradas, pero no al resto de páginas de la web, podemos simplemente indicarle que deje de añadir la classe hentry para el resto de páginas.
Hay diferentes maneras de conseguir esto. Una de ellas sería añadir un filtro en el fichero functions.php para evitar que se añada la etiqueta hentry en aquellas entradas que no sean de tipo post.
El código sería algo del siguiente estilo (visto en un hilo en el foro de ayuda oficial de WordPress.org):
/* Remove Hentry
/* ------------------------------------ */
function remove_hentry( $classes ) {
if( !is_single() ) {
$classes = array_diff($classes, array('hentry'));
return $classes;
} else {
return $classes;
}
}
add_filter( 'post_class', 'remove_hentry' );
Añadir las etiquetas vcard author y updated a algunas o todas las secciones que se vayan a indexar
Esta es la opción por la que me decanté en su momento para el desarrollo WordPress que estaba realizando para un cliente. Aunque opino que quizá no es lo más correcto a nivel semántico, hay motivos por los cuales podría ser interesante seguir esta ruta.
Por ejemplo, algunas de las páginas estáticas y páginas personalizadas de este proyecto, como el portfolio, seguían teniendo una componente bastante personal, y teniendo en cuenta que a nivel interno WordPress tiene metadatos del autor y de la última fecha de actualización para todos los tipos de entrada -no solo las del blog- técnicamente lo hace factible.
Súmale el hecho de que desde la perspectiva SEO me veía reticente a restar estrategias que pudieran ayudar a maximizar el alcance de cada una de las secciones de la web de mi cliente, para decantarme finalmente por esta alternativa (aunque sobre esto último, un comentario más abajo sobre posibles optimizaciones).
Hay al menos dos maneras de abordar esta tarea:
Con filtro en functions.php
Siguiendo con la estrategia de modificar el fichero functions.php, en el hilo anterior otro usuario aporta una solución elegante y mejorada con respecto a la anterior, que nos permite obtener un poco de ambos mundos:
//add hatom data
function add_suf_hatom_data($content) {
$t = get_the_modified_time('F jS, Y');
$author = get_the_author();
$title = get_the_title();
if (is_home() || is_singular() || is_archive() ) {
$content .= '<div class="hatom-extra" style="display:none;visibility:hidden;"><span class="entry-title">' .$title. '</span> was last modified: <span class="updated">' .$t. '</span> by <span class="author vcard"><span class="fn">' .$author. '</span></span></div>';
}
return $content;
}
add_filter('the_content', 'add_suf_hatom_data');
Lo que hace el código anterior es añadir las clases faltantes a las secciones que nos interesen, como por ejemplo la página principal o los archivos, y además se opta por añadirlo todo en un div oculto para que no se muestre en dichas secciones, con el objetivo de respetar el funcionamiento esperado.
Modificando las plantillas del tema de WordPress
Otra opción es estudiar el código del tema con el que estamos trabajando e intentar insertar directamente los metadatos necesarios ahí donde estimemos oportuno.
Por ejemplo, el tema base usado en este proyecto hace uso extensivo de templates para definir cada una de las partes que componen la plantilla del tema, y en el archivo /template-parts/content.php llama a una función específicamente ideada por el autor (en /inc/template-tags.php) que se encarga del renderizado personalizado del nombre del autor, fecha de publicación, etc. y que afortunadamente añade las classes author vcard y updated en la entrada.
En este caso sería tan sencillo como anotar el código para la llamada a esta función en el template para las entradas del blog y añadirla al template para las páginas estáticas y entradas personalizadas, que en este caso caso faltaban. Por ejemplo, portado al archivo /template-parts/content-page.php:
... <header class="entry-header"> <?php the_title( '<h1 class="entry-title">', '</h1>' ); ?> </header> // Añadir la descripción meta, pero no mostrarla en la página (se detecta igualmente) <div class="entry-meta" style="display:none"> <?php custom_theme_posted_on(); // la función que contiene el código que añade las classes "author vcard" y "updated" ?> </div> ...
Es posible que en otro tema (o si estás desarrollando el tuyo propio) no dispongas de una función similar, pero deberías encontrar un código similar al propuesto en la solución anterior y en caso contrario (¡entonces estarías obteniendo el error en todas las páginas de tu sitio web!) añadirlo también en las entradas del blog.
Lo importante a recordar es que en el momento en que se añade la clase hentry, en el código HTML final debe querdar una jerarquía de clases completa según la especificación hatom, con la siguiente pinta:
<div class="hentry"> <h1 class="entry-title"> El título </h1> <div class="entry"> <span class="... updated"> La fecha </span> ... <span class="vcard author"><span class="fn"> ... </div> </div>
Para mostrar la fecha, el código PHP que se suele usar es algo del siguiente estilo:
<p class="post-date date updated"><?php the_time('j M, Y'); ?></p>
Y para el autor:
<span class="vcard author"><span class="fn"> <a href="https://plus.google.com/+perfil" target="_blank" rel="author"><?php the_author() ?></a> </span></span>
Otras mejoras
Un poco más arriba comentaba que añadir la información hAtom en todas las secciones quizá no sea una buena práctica para deshacerse de estos errores de datos estructurados ya que fue específicamente pensada para ser usada en entradas de tipo blog, artículos o notícias, aunque por conveniencia y para no arriesgar el ranking SEO podríamos añadirlas ya que puedan ayudar a posicionar bien en Google.
El caso es que una solución probablemente mejor (la dejo como deberes) sería optar por no incluir la clase hentry en aquellas páginas que no sean una entrada de blog o con finalidad similar, sinó encontrar la especificación idónea para cada caso y preparar el tema de WordPress para que la implemente.
Por ejemplo, para las entradas personalizadas o ‘custom types’, en el caso de desarrollar un portfolio de proyectos (bastante típico) podríamos hacer uso de la especificación hResume. Para productos y servicios, la hProduct; para análisis y comparativas, la hReview; y así para los contenidos típicos que tengan un equivalente en forma de microformato.
De esta manera estaríamos haciendo un mejor uso de la especificación, y seguramente también tenga un impacto aún mejor en nuestro posicionamiento SEO ya que estamos describiendo de manera más fidedigna el tipo de contenidos que damos de alta, algo que los mejores motores tienen en cuenta.
Y hasta aquí…
Si eres un desarrollador justo de tiempo, tanto si esperabas entender un poco más sobre el problema como encontrar una solución rápida, espero poder haberte ayudado a resolver el problema.
Si eres un usuario final intentando mejorar la presencia de su sitio WordPress, espero igualmente haberte sido de ayuda. Si finalmente resulta ser un tema demasiado complicado y necesitas soporte personalizado, estoy disponible como freelance para mandarte un cable, puedes contactarme a través del formulario de contacto 😉
Gracias, he estado buscando esta info por bastante tiempo.